国产大模型编程能力登顶全球:GLM-5.1与Qwen3.6-Plus双杀,价格仅为GPT九分之一

最新发布的数据令人瞩目——国产大模型在编程能力领域已跃居全球领先地位。
具体什么情况
智谱AI的GLM-5.1与阿里巴巴的Qwen3.6-Plus相继发布,形成了直接的正面交锋。
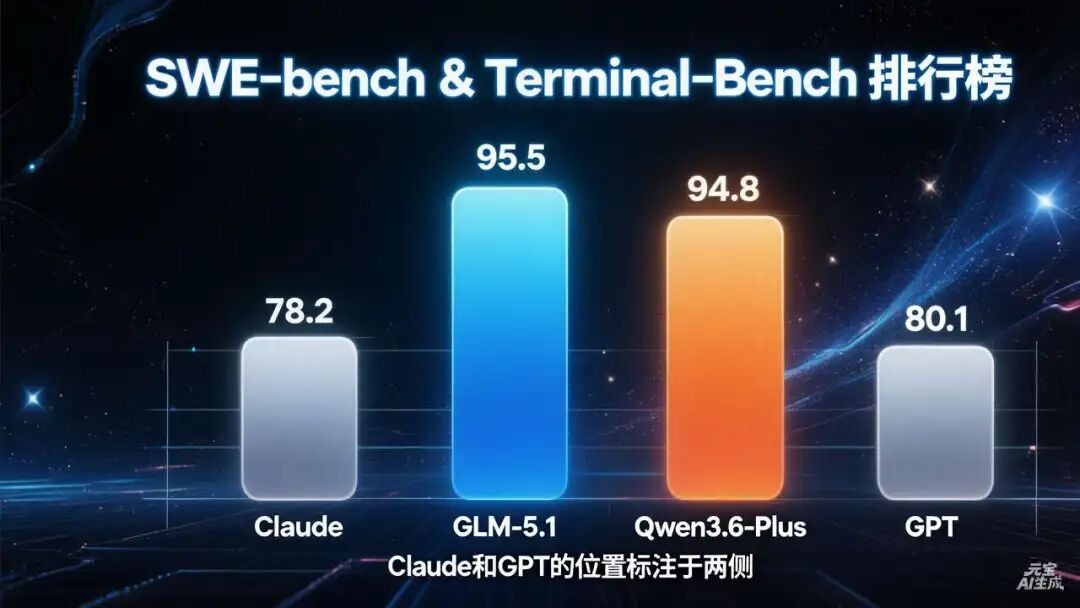
GLM-5.1在SWE-bench Pro评测中取得58.4%的成绩,位居开源模型全球首位,超越了Claude Opus 4.5与GPT-5.4等顶尖闭源模型
Qwen3.6-Plus的表现更为激进,在Terminal-Bench 2.0与OmniDocBench两项权威评测中均斩获全球第一,在中文编程场景下更是展现出统治级表现。
综合来看,国产大模型已实现从"追赶者"到"领跑者"的角色转变。
价格才是真正的杀招
性能突破之外,更具冲击力的是显著的成本优势。
Qwen3.6-Plus的定价为输入约2元/百万Token、输出约10元/百万Token,而GPT-5.4的对应价格分别约为18元与86元。经测算,Qwen3.6-Plus的使用成本仅为GPT-5.4的九分之一。
这意味着在同等预算下可获得九倍的有效调用量,使团队全员高频使用成为可能,无需担忧成本压力。
GLM-5.1则采用了差异化的技术路径,支持长达8小时的无中断自主执行,特别适用于需要长时间无人值守、一次性完成的Agent任务场景。

选哪个
这一选择并无绝对标准,需结合具体应用场景:
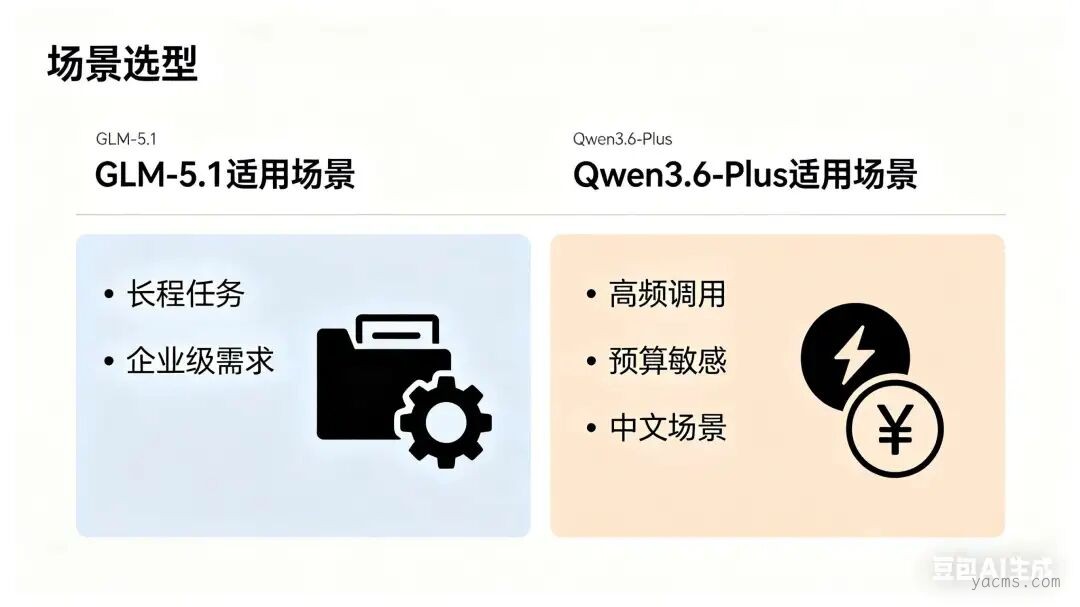
GLM-5.1更适用于长周期任务,可将企业级项目交由其自主运行而无需人工干预;Qwen3.6-Plus则更适合高频次、短周期的调用场景,在此类使用模式下成本优势更为显著。
具体而言,英文开源代码修复场景建议选用GLM-5.1,中文技术文档处理则推荐Qwen3.6-Plus;对于预算受限的团队,Qwen3.6-Plus应为优先选择。
最后
此次国产模型的突破标志着其已摆脱"可用但平庸"的阶段,在特定场景下实现了真正的技术领先。
加之其极具竞争力的定价策略,势必对OpenAI等厂商的商业模式形成显著冲击,未来数月的市场反应将更为清晰。
虽然技术选型复杂度的提升为开发者带来了"选择困难",但这恰恰印证了市场竞争格局的优化——我们终于拥有了真正意义上的选择权。
评论
发表评论